Тестирование Qwen3.6-27B
Перепробовал за последние месяцы много разных локальных моделей. У меня есть свой тест для них — файл с подробным заданием для редактора заметок под Linux на Rust. Подсветка синтаксиса (несложно, есть из коробки в системном компоненте) и панель предварительного просмотра, которая должна показывать отформатированный текст. В целом, довольно похоже на моё приложение Swifty Notes, но на Rust.
Так вот, Qwen3.6-27B пока что единственная модель, которая добралась до финиша. Работала она в течение 3 дней (не круглосуточно, а только когда я был у компа и мог её направить). Редко, но всё-таки модель испытывала проблемы с вызовом инструментов. Иногда не могла отредактировать файл и останавливалась — приходилось просить её попробовать ещё раз. В целом эту часть я бы оценил на 4 из 5.
Самое главное — модель не ходила кругами. Rust здесь очень удачный выбор: если есть ошибка, то проект просто не компилируется. А в сочетании с тем, что техническое задание требует сначала писать тесты, а потом код (Test Driven Development), очень много проблем находится и исправляется на самых ранних стадиях. И тут модель себя показала неплохо. Достаточно быстро исправляла ошибки, следовала инструкциям из ТЗ и изучала документацию, если вдруг использовала несуществующий API или просто нужно было проверить, что доступно. Тут твёрдая 4 из 5.
Размер модели — 17.5 гигабайт. Я скачал её через LM Studio, но запускал через llama.cpp — на удивление, скорость работы моделей там гораздо выше, хотя вроде бы LM Studio её же и использует. Возможно, более свежие версии llama.cpp просто уже более оптимизированы.
В видеопамять модель не влезает целиком (у меня 16 ГБ), поэтому частично работала на CPU, что очень сказалось на скорости. 15.94 ГБ видеопамяти и ещё около 12 ГБ оперативной памяти занимало всё это чудо в пике (когда контекст уже был близок к заполнению). Размер контекста я выставил 64k — поначалу хватало неплохо, но ближе к концу, когда объём кода вырос, модель довольно часто делала сжатие контекста. Хотя в целом с задачей такого размера модель справилась.
Скорость работы я бы оценил на 2 из 5.
Когда модель отрапортовала, что всё готово, я запустил приложение и увидел, что в панели просмотра у меня просто текстом HTML вместо рендера. Пришлось попросить модель это исправить, и спустя ещё часа полтора-два я получил приемлемый результат. Но стоит упомянуть, что с флагманскими моделями тоже такое сплошь и рядом — с первого раза большие задачи, как правило, не получаются, требуются правки и уточнения.
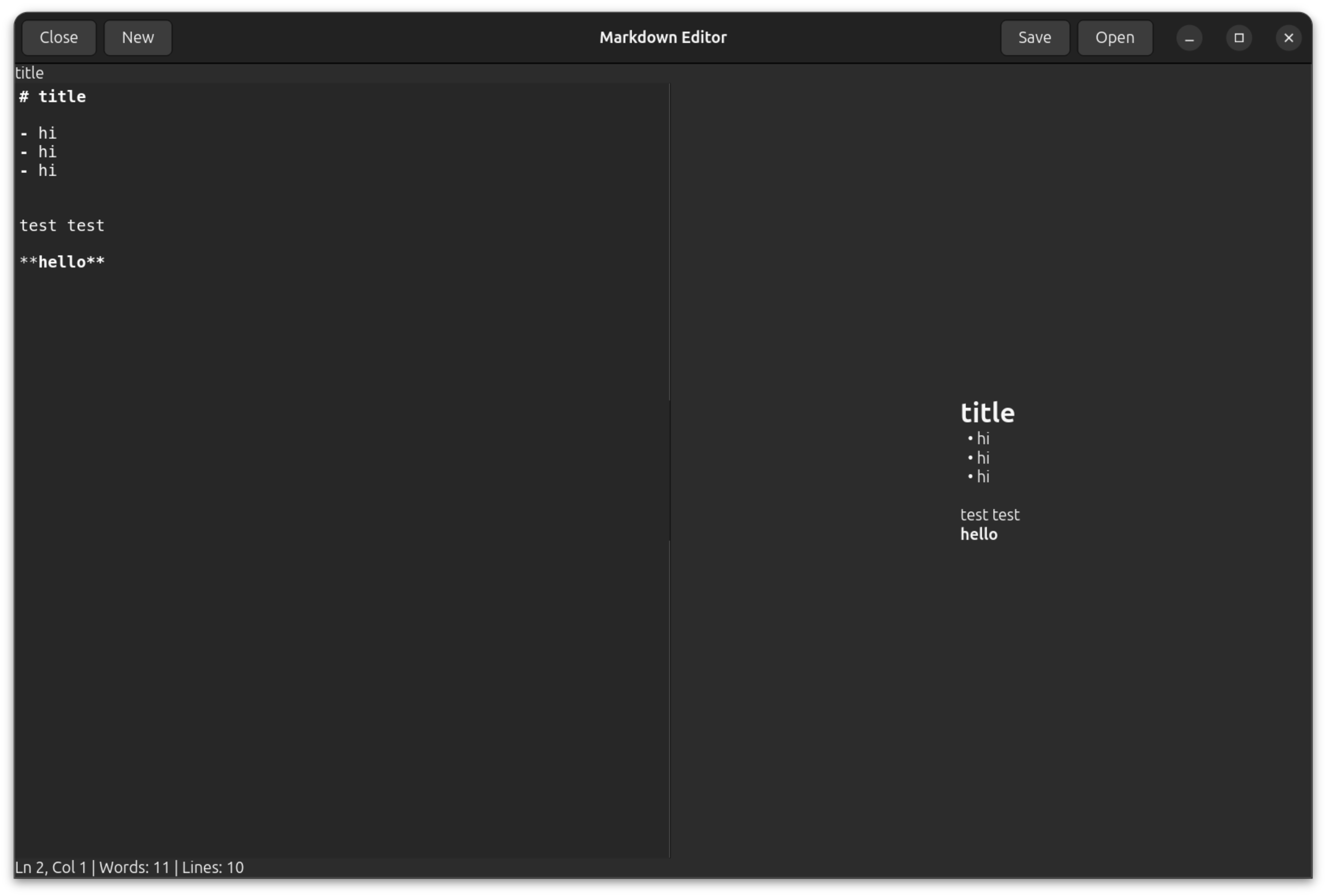
Итого: Claude Code сделал бы это задание минут за 20–30, и, скорее всего, ещё минут 20–30 я бы потратил на доделывание. Округлим до 1 часа. С Qwen3.6-27B на это понадобилось в сумме около 20 часов работы без остановки, то есть примерно 3 полноценных рабочих дня. Конечно, большую часть времени ты просто сидишь и смотришь, как модель работает. Скорость генерации на предварительных тестах, которые мне помог провести Claude, на моём железе была 12–18 токенов в секунду.
Разница в скорости огромная. Результат удовлетворительный. Многое из требуемого функционала просто не работает, но я виню в этом размер контекста — модели тяжело держать столько кода в памяти.
Тем не менее результатом я доволен. Это вселяет веру в то, что программирование с помощью локальных моделей на обычном железе возможно. А ведь ещё год назад даже облачные модели косячили похожим образом, а локальные модели такого размера и вовсе для программирования не годились. Возможно, через год прогресс приведёт к тому, что для небольших проектов подписки станут не нужны. Да и тенденция к тому, что открытые бесплатные модели уже догнали флагманов от OpenAI и Anthropic, мне нравится.