Testing Qwen3.6-27B
Over the past few months I've tried out a lot of different local models. I have my own kind of benchmark for them — a file with a detailed spec for a notes editor for Linux written in Rust. Syntax highlighting (not hard, it's available out of the box in the system component) and a preview panel that should render formatted text. Overall, it's pretty similar to my Swifty Notes app, but in Rust.
So, Qwen3.6-27B is so far the only model that's made it to the finish line. It worked for 3 days (not around the clock, only when I was at the computer and could guide it). Occasionally the model had issues with tool calls. Sometimes it couldn't edit a file and would just stop — I had to ask it to try again. Overall I'd give this part a 4 out of 5.
The most important thing is that the model didn't go in circles. Rust is a great choice here: if there's an error, the project simply won't compile. Combined with the fact that the spec requires writing tests first and then the code (Test Driven Development), a lot of issues get caught and fixed at the earliest stages. And here the model performed pretty well. It fixed errors fairly quickly, followed the instructions from the spec, and consulted documentation if it suddenly used a nonexistent API or just needed to check what was available. A solid 4 out of 5 here.
The model size is 17.5 GB. I downloaded it through LM Studio but ran it via llama.cpp — surprisingly, the performance there is significantly better, even though LM Studio supposedly uses llama.cpp under the hood. Maybe more recent versions of llama.cpp are just better optimized.
The model doesn't fit entirely into VRAM (I have 16 GB), so it ran partially on the CPU, which heavily impacted speed. This whole thing was eating 15.94 GB of VRAM and another ~12 GB of RAM at peak (when the context was nearly full). I set the context size to 64k — at first that was plenty, but towards the end, as the codebase grew, the model would compact the context fairly often. Still, overall it handled a task of this size.
I'd give the speed a 2 out of 5.
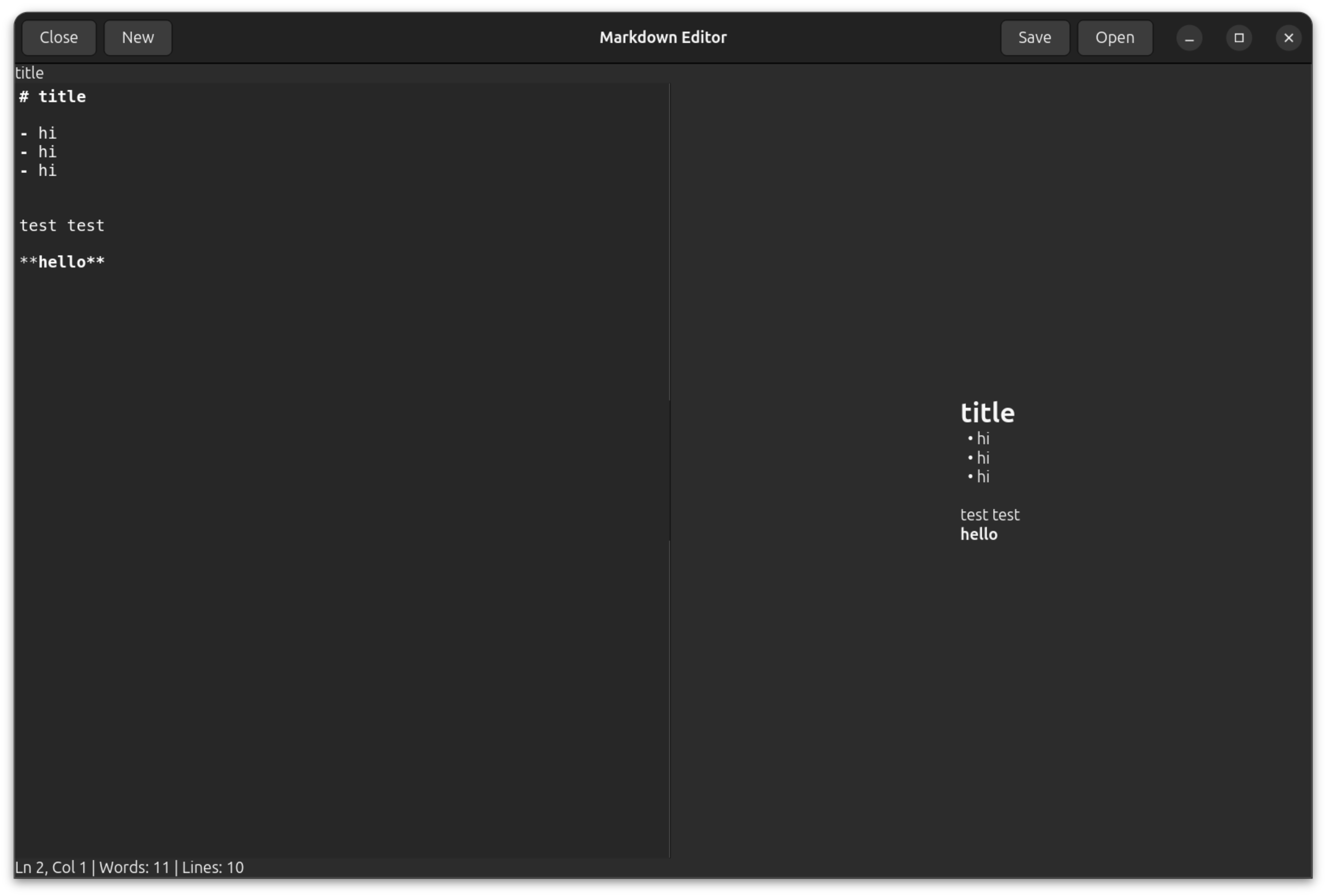
When the model reported that everything was done, I launched the app and saw raw HTML text in the preview panel instead of a rendered view. I had to ask the model to fix it, and after another hour and a half or two I got an acceptable result. That said, it's worth mentioning that this kind of thing happens all the time even with flagship models — large tasks rarely work on the first try and usually require revisions and clarifications.
Bottom line: Claude Code would've done this task in 20–30 minutes, and I'd probably spend another 20–30 minutes finishing things up. Let's round up to 1 hour. With Qwen3.6-27B it took about 20 hours of continuous work in total, roughly 3 full working days. Of course, most of that time you're just sitting there watching the model work. Generation speed on the preliminary tests Claude helped me run was 12–18 tokens per second on my hardware.
The speed difference is huge. The result is acceptable. A lot of the required functionality just doesn't work, but I blame the context size for that — it's hard for models to hold that much code in memory.
Still, I'm happy with the result. It gives me hope that programming with local models on regular hardware is feasible. A year ago even cloud models were making similar mistakes, and local models of this size were simply not suitable for programming at all. Maybe in another year progress will get us to the point where subscriptions won't be needed for small projects. And I really like the trend that open-source free models have already caught up with the flagships from OpenAI and Anthropic.